
RANSAC算法之前了解过相关的原理,这两天利用晚上闲暇的时间,看了一下RANSAC算法的Python代码实现,这方面的资料很多了,这里就不在重复。在分析该RANSAC.py代码之前,想用自己的对RANSAC的理解对其做下总结。
在实际应用中获取到的数据,常常会包含有噪声数据,这些噪声数据会使对模型的构建造成干扰,我们称这样的噪声数据点为outliers,那些对于模型构建起积极作用的我们称它们为inliers,RANSAC做的一件事就是先随机的选取一些点,用这些点去获得一个模型(这个讲得有点玄,如果是在做直线拟合的话,这个所谓的模型其实就是斜率),然后用此模型去测试剩余的点,如果测试的数据点在误差允许的范围内,则将该数据点判为inlier,否则判为outlier。inliers的数目如果达到了某个设定的阈值,则说明此次选取的这些数据点集达到了可以接受的程度,否则继续前面的随机选取点集后所有的步骤,不断重复此过程,直到找到选取的这些数据点集达到了可以接受的程度为止,此时得到的模型便可认为是对数据点的最优模型构建。
在Cookbook/RANSAC中给出的是一个用RANSAC做直线拟合的例子。这个例子非常的直观,而且代码也很简短易懂,为便于后面详细解读该代码,这里把它贴出来:
# -*- coding: utf-8 -*-
import numpy
import scipy # use numpy if scipy unavailable
import scipy.linalg # use numpy if scipy unavailable
import pylab
## Copyright (c) 2004-2007, Andrew D. Straw. All rights reserved.
def ransac(data,model,n,k,t,d,debug=False,return_all=False):
"""fit model parameters to data using the RANSAC algorithm
This implementation written from pseudocode found at
http://en.wikipedia.org/w/index.php?title=RANSAC&oldid=116358182
Given:
data - a set of observed data points # 可观测数据点集
model - a model that can be fitted to data points #
n - the minimum number of data values required to fit the model # 拟合模型所需的最小数据点数目
k - the maximum number of iterations allowed in the algorithm # 最大允许迭代次数
t - a threshold value for determining when a data point fits a model #确认某一数据点是否符合模型的阈值
d - the number of close data values required to assert that a model fits well to data
Return:
bestfit - model parameters which best fit the data (or nil if no good model is found)
"""
iterations = 0
bestfit = None
besterr = numpy.inf
best_inlier_idxs = None
while iterations < k:
maybe_idxs, test_idxs = random_partition(n,data.shape[0])
maybeinliers = data[maybe_idxs,:]
test_points = data[test_idxs]
maybemodel = model.fit(maybeinliers)
test_err = model.get_error( test_points, maybemodel)
also_idxs = test_idxs[test_err < t] # select indices of rows with accepted points
alsoinliers = data[also_idxs,:]
if debug:
print 'test_err.min()',test_err.min()
print 'test_err.max()',test_err.max()
print 'numpy.mean(test_err)',numpy.mean(test_err)
print 'iteration %d:len(alsoinliers) = %d'%(
iterations,len(alsoinliers))
if len(alsoinliers) > d:
betterdata = numpy.concatenate( (maybeinliers, alsoinliers) )
bettermodel = model.fit(betterdata)
better_errs = model.get_error( betterdata, bettermodel)
thiserr = numpy.mean( better_errs )
if thiserr < besterr:
bestfit = bettermodel
besterr = thiserr
best_inlier_idxs = numpy.concatenate( (maybe_idxs, also_idxs) )
iterations+=1
if bestfit is None:
raise ValueError("did not meet fit acceptance criteria")
if return_all:
return bestfit, {'inliers':best_inlier_idxs}
else:
return bestfit
def random_partition(n,n_data):
"""return n random rows of data (and also the other len(data)-n rows)"""
all_idxs = numpy.arange( n_data )
numpy.random.shuffle(all_idxs)
idxs1 = all_idxs[:n]
idxs2 = all_idxs[n:]
return idxs1, idxs2
class LinearLeastSquaresModel:
"""linear system solved using linear least squares
This class serves as an example that fulfills the model interface
needed by the ransac() function.
"""
def __init__(self,input_columns,output_columns,debug=False):
self.input_columns = input_columns
self.output_columns = output_columns
self.debug = debug
def fit(self, data):
A = numpy.vstack([data[:,i] for i in self.input_columns]).T
B = numpy.vstack([data[:,i] for i in self.output_columns]).T
x,resids,rank,s = scipy.linalg.lstsq(A,B)
return x
def get_error( self, data, model):
A = numpy.vstack([data[:,i] for i in self.input_columns]).T
B = numpy.vstack([data[:,i] for i in self.output_columns]).T
B_fit = scipy.dot(A,model)
err_per_point = numpy.sum((B-B_fit)**2,axis=1) # sum squared error per row
return err_per_point
def test():
# generate perfect input data
n_samples = 500
n_inputs = 1
n_outputs = 1
A_exact = 20*numpy.random.random((n_samples,n_inputs) ) # x坐标
perfect_fit = 60*numpy.random.normal(size=(n_inputs,n_outputs) ) # the model(斜率)
B_exact = scipy.dot(A_exact,perfect_fit) # y坐标
assert B_exact.shape == (n_samples,n_outputs) #验证y坐标数组的大小
#pylab.plot( A_exact, B_exact, 'b.', label='data' )
#pylab.show()
# add a little gaussian noise (linear least squares alone should handle this well)
A_noisy = A_exact + numpy.random.normal(size=A_exact.shape ) # x坐标添加高斯噪声
B_noisy = B_exact + numpy.random.normal(size=B_exact.shape ) # y坐标....
#pylab.plot( A_noisy, B_noisy, 'b.', label='data' )
if 1:
# add some outliers
n_outliers = 100 # 500个数据点有100个是putliers
all_idxs = numpy.arange( A_noisy.shape[0] )
numpy.random.shuffle(all_idxs) # 索引随机排列
outlier_idxs = all_idxs[:n_outliers] # 选取all_idxs前100个做outlier_idxs
non_outlier_idxs = all_idxs[n_outliers:] # 后面的不是outlier_idxs
A_noisy[outlier_idxs] = 20*numpy.random.random((n_outliers,n_inputs) ) # 外点的横坐标
B_noisy[outlier_idxs] = 50*numpy.random.normal(size=(n_outliers,n_outputs) ) # 外点的纵坐标
#pylab.plot( A_noisy, B_noisy, 'b.', label='data' )
#pylab.show()
# setup model
all_data = numpy.hstack( (A_noisy,B_noisy) ) # 组成坐标对
input_columns = range(n_inputs) # the first columns of the array
output_columns = [n_inputs+i for i in range(n_outputs)] # the last columns of the array
debug = False
model = LinearLeastSquaresModel(input_columns,output_columns,debug=debug)
linear_fit,resids,rank,s = scipy.linalg.lstsq(all_data[:,input_columns],
all_data[:,output_columns])
# run RANSAC algorithm
ransac_fit, ransac_data = ransac(all_data,model,
50, 1000, 7e3, 300, # misc. parameters
debug=debug,return_all=True)
if 1:
import pylab
sort_idxs = numpy.argsort(A_exact[:,0]) # 对A_exact排序, sort_idxs为排序索引
A_col0_sorted = A_exact[sort_idxs] # maintain as rank-2 array
if 1:
pylab.plot( A_noisy[:,0], B_noisy[:,0], 'k.', label='data' )
pylab.plot( A_noisy[ransac_data['inliers'],0], B_noisy[ransac_data['inliers'],0], 'bx', label='RANSAC data' )
else:
pylab.plot( A_noisy[non_outlier_idxs,0], B_noisy[non_outlier_idxs,0], 'k.', label='noisy data' )
pylab.plot( A_noisy[outlier_idxs,0], B_noisy[outlier_idxs,0], 'r.', label='outlier data' )
pylab.plot( A_col0_sorted[:,0],
numpy.dot(A_col0_sorted,ransac_fit)[:,0],
label='RANSAC fit' )
pylab.plot( A_col0_sorted[:,0],
numpy.dot(A_col0_sorted,perfect_fit)[:,0],
label='exact system' )
pylab.plot( A_col0_sorted[:,0],
numpy.dot(A_col0_sorted,linear_fit)[:,0],
label='linear fit' )
pylab.legend()
pylab.show()
if __name__=='__main__':
test()
上面代码跟原版的代码相比,我删除了一些冗余的东西。在test()中做的是直线拟合。在看test()部分之前,我们先来看看RANSAC部分的代码,传入RANSAC函数中的参数有8个,前面6个是比较重要的。data就是全部的数据点集,model注释里给出的是拟合点集的模型,放到这个直线拟合的实例下,就是斜率,n就是拟合时所需要的最小数据点数目,放在这里直线拟合的例子中,就是用于选取的用于去做直线拟合的数据点数目,k就是最大允许的迭代次数,t是人为设定的用于判断误差接受许可的范围。这几个参数的含义知道了,剩下的就是理解while循环里面的内容了。在每一次循环中,选对所有的数据点做一个随机的划分,将数据点集分成两堆,分别对应maybeinliers和test_points,maybeinliers这部分数据用于做直线拟合,这里直线拟合采用的是最小二乘法,得到拟合到的直线的斜率maybemodel,然后用该直线及测试数据的横坐标去估计测试数据的纵坐标,也就是在该模型下测试数据的估计值,测试数据的估计值和测试数据的真实值做一个平方和便得到误差,将得到的误差分别和设定的可接受误差进行判断,在误差范围内的判定为inlier,否者判断为outlier。当inliers的数目达到了设定的数目的要求是,再讲inliers和maybeinliers放一下再做一下最小二乘拟合,便得到最终的最佳斜率了。
test()部分的内容很简单,先生成在某条直线上的一些离散点,这里某条直线的斜率就是精确的模型:
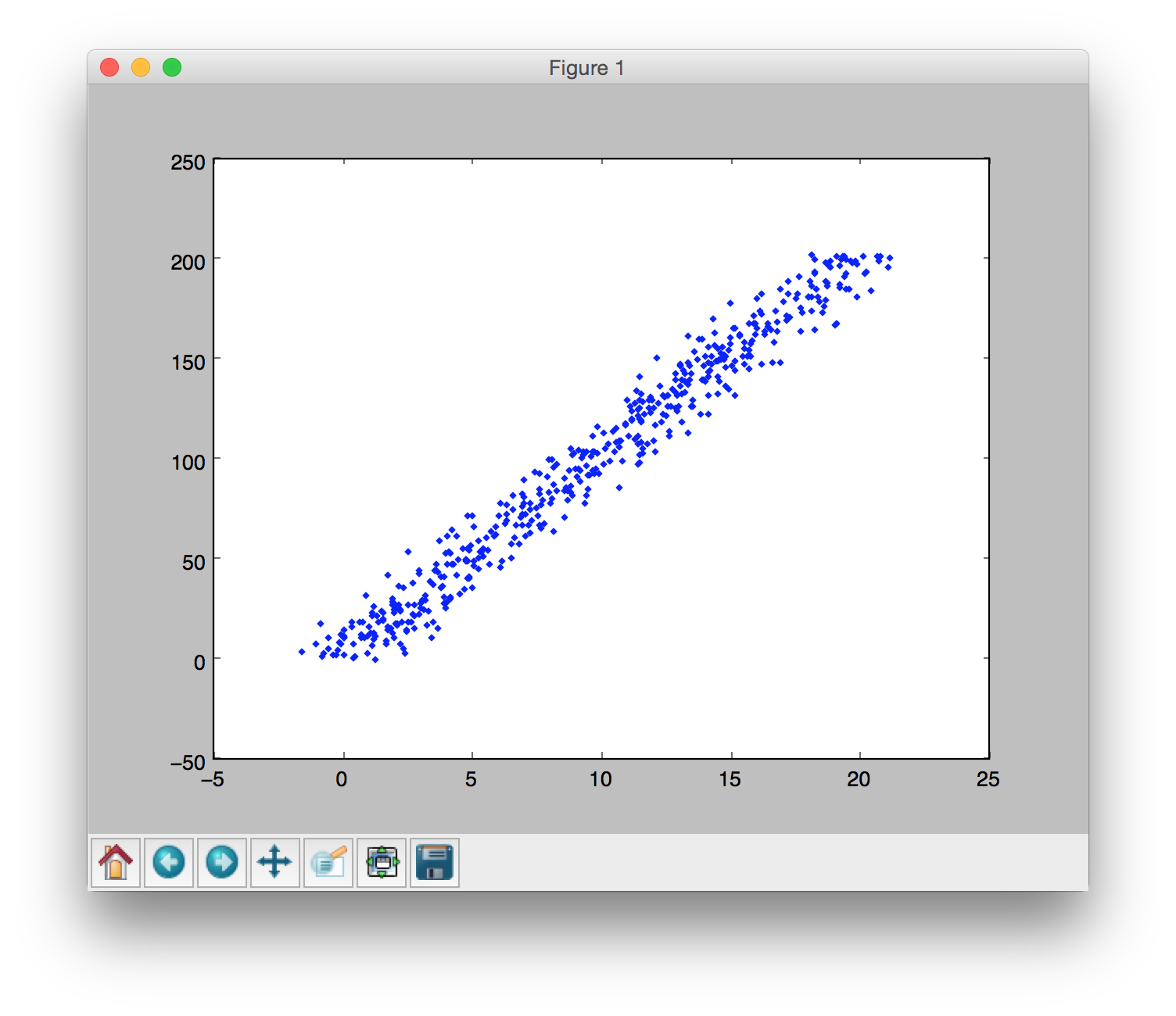
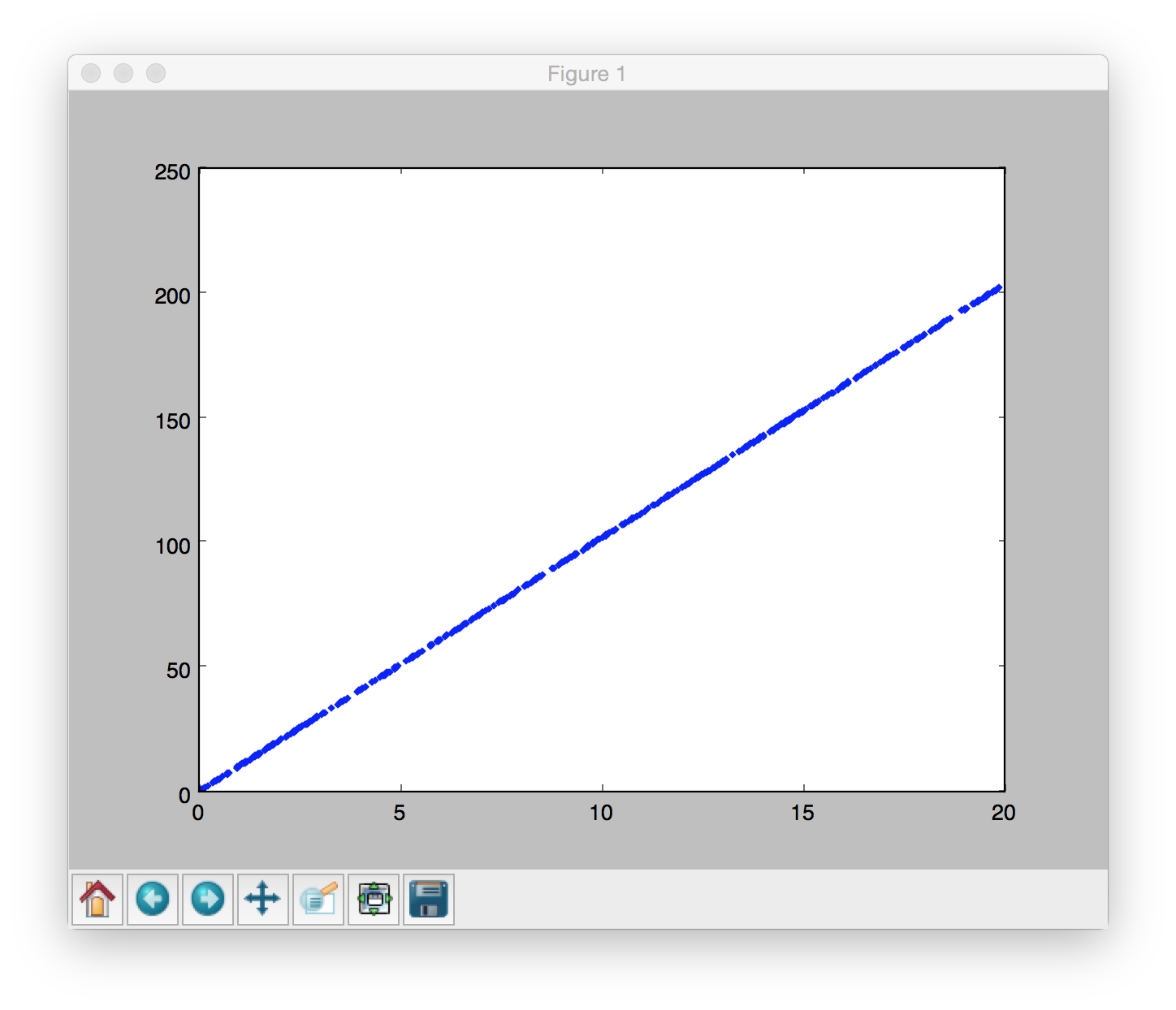 然后添加高斯平稳高斯噪声:
然后添加高斯平稳高斯噪声:
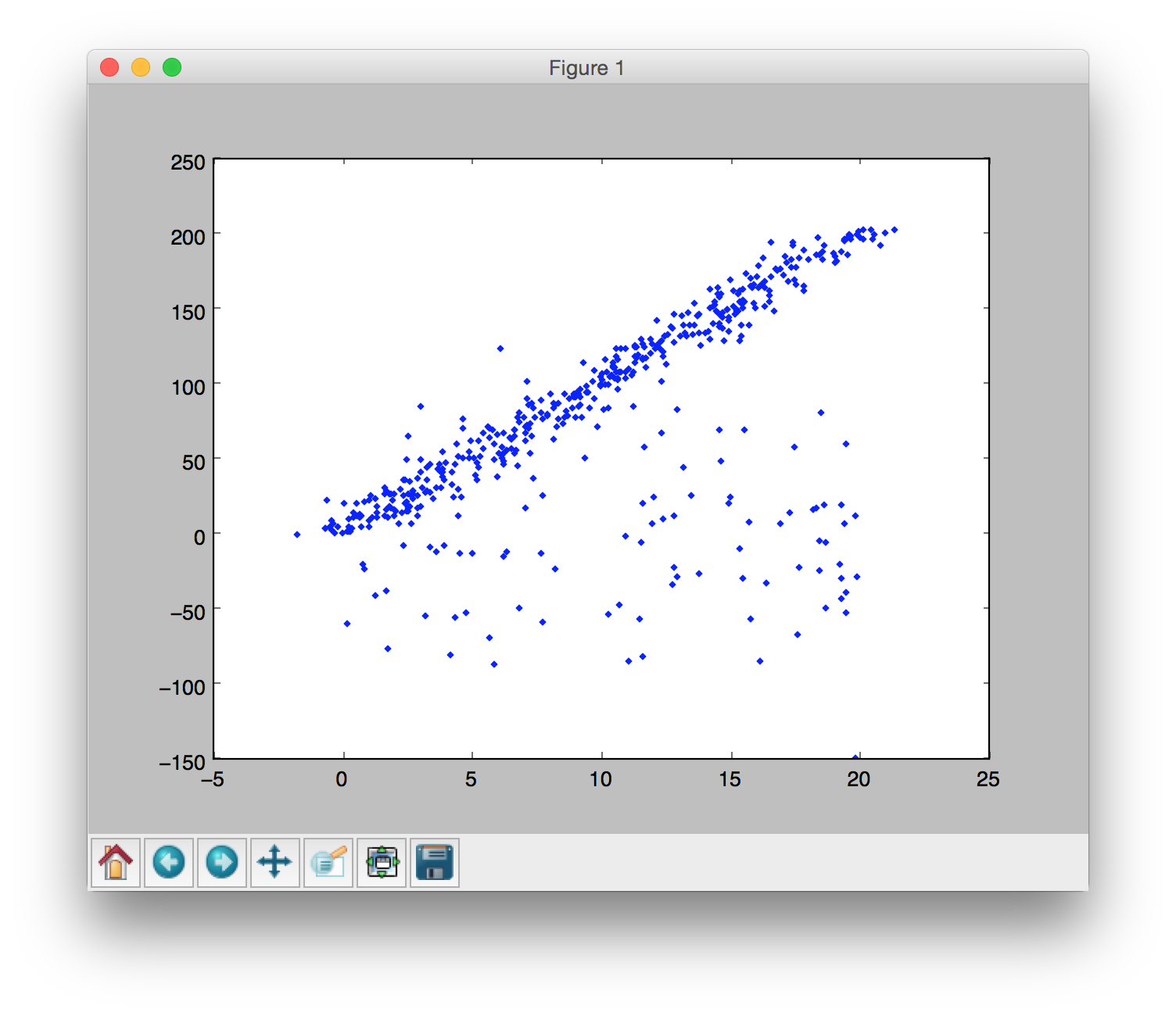
 将其中的某些点变为outliers:
将其中的某些点变为outliers:
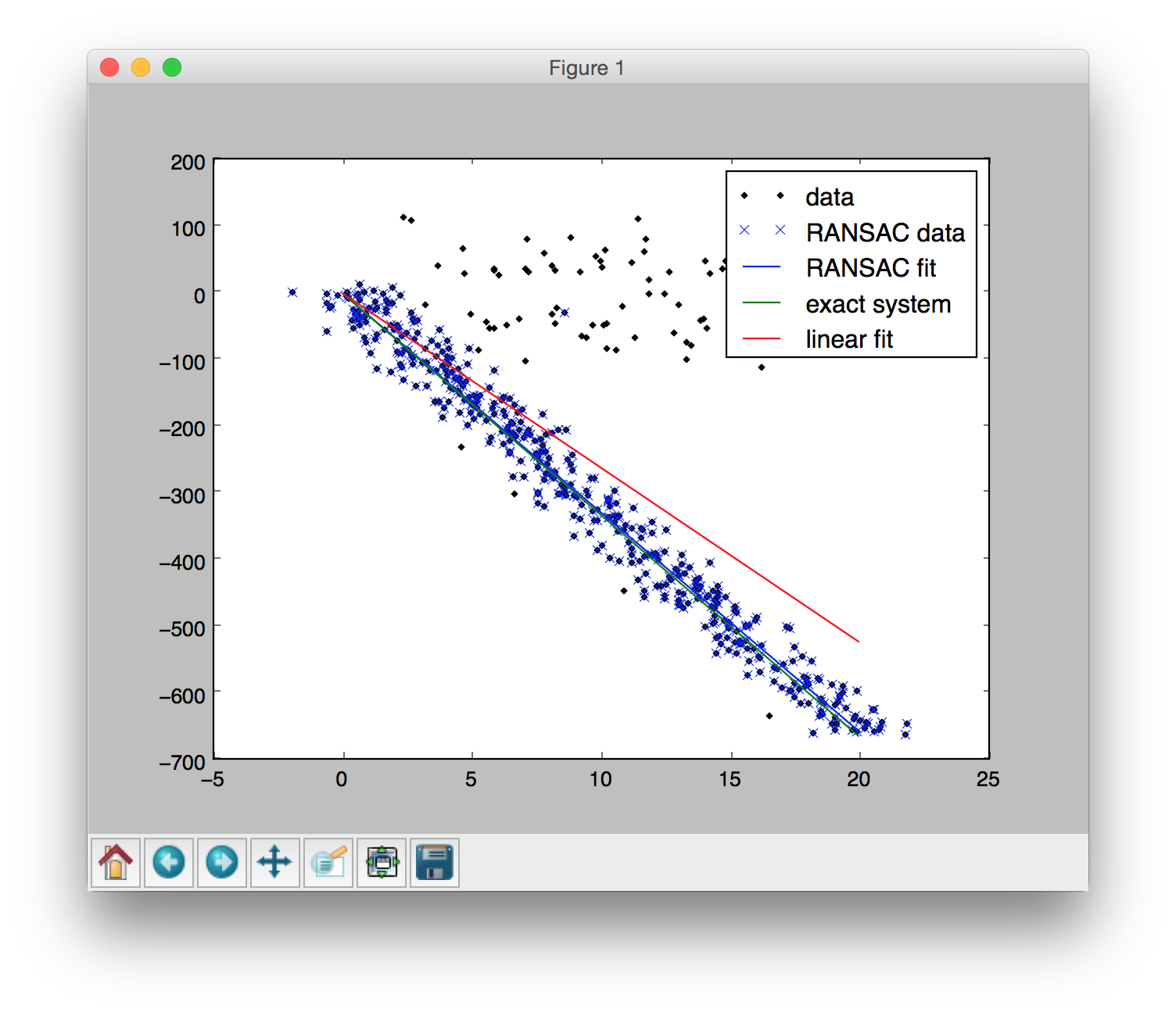
 最后用RANSAC拟合出来的结果如下:
最后用RANSAC拟合出来的结果如下:
 整个过程就酱紫,后面有时间继续前面在BoW图像检索Python实战用RANSAC做一个重排过程。
整个过程就酱紫,后面有时间继续前面在BoW图像检索Python实战用RANSAC做一个重排过程。