
真不能再挖坑了,前面挖聊很多坑都没来得及填,从今往后,能写多少就是多少。Sequential projection learning for hashing这篇文章去年就阅读了,当时阅读完没来得及做笔记,这一段时间又重新拿来品读了一年天,并对其中的公式进行了推导,这篇文章作者主页上有slide,讲得挺好的。下面是自己的一些推导,由于公式编辑起来不急手写得快,所以就用笔记代替了。

这里标号为1推导的是paper目标函数项中的第一项,目标函数第二项是通过最大化信息熵而来的,关于到最后为神马转化为了求信息熵最大化,仍本小子一一道来。
有了第一项,还远远不够,因为第一项只保持能够在带标记的样本上获得很高的准确率,当不能保证在未标记的样本上也能获得较高的准确率,也就是过拟合问题,即在训练样本上performance很well,但是在测试样本上很bad。所以为了避免出现这个问题,作者对spectral hashing中要求的编码位求和相加得为0进行了分析与证明,最后得出要要求编码位求和相加为0就是要求信息熵最大。paper中的一个图很好的说明了上面这个情况:
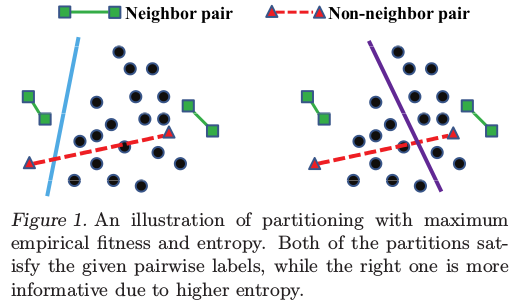
为便于理解,假设上面就是简单的二维平面,在左图中,虽然对于带标记的样本,其编码位(这里只有一位)相加求和为0,但对于未标记的样本,其编码位相加求和显然不会等于0,而且,可以看到,落入分类面右边的可能性要远比左边的要大;而对于右图,其划分相比比较均匀,不仅满足了标记样本的要求,而且也满足了非标记样本的要求(编码位求和相加为0),而且,大概的示意出了落入两边的概率为50%。由此,对于右图,其包含的信息熵相比与左图,要更大。用一句话概括上面第二项为神马要进行这样的约束,其实就是要求编码位求和相加为0,并经过转换,化为信息熵最大的约束。
再回到上面手写笔记那幅图,标号2对应位置有关于S更新过程的推导,推导过程还算简单,对其求微分便可。本小子不太理解的地方还是这个S更新过程的物理意义。
Reference:
1:Sequential Projection Learning for Hashing with Compact Codes